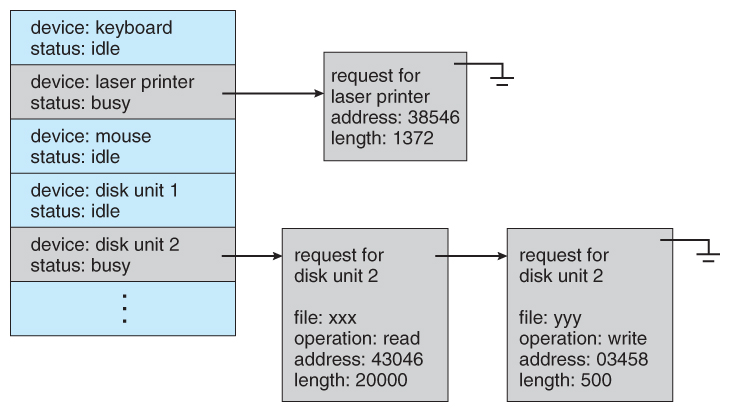
Põhimälu -aadressidega baidimasiiv - ainuke suurem salvestuspiirkond, mille poole CPU saab otse pöörduda • Protsessor loeb mälust käske ja andmeid
–käsu lugemine;
–esimese argumendi lugemine;
–teise argumendi lugemine;
–käsu täitmine;
–tulemuse mällu tagasi salvestamine.
Mäluhalduse lihtsaim käsitlus
• Käivitatavatele programmi protsessidele mälu
hõivamine ja mälu vabastamine, kui seda enam ei
vajata. Mäluhaldus on arvutisüsteemi töö eluline
osa.
• Virtuaalmälu süsteemid lahutavad protsesside
poolt kasutatavad mäluaadressid tegelikest
füüsilistest aadressidest, kirjutades osa mälu
sisust kettale ja suurendades nii efektiivse vaba
mälu mahtu
Mälu jagamine
• Kuigi erinevate protsesside mälu on tavaliselt
üksteise eest kaitstud, vajavad erinevad
protsessid siiski vahetevahel võimalust
informatsiooni jagada ja peavad seetõttu
omama juurdepääsu samale mälupiirkonnale
• Jagatatud mälu on üks kiirematest viisidest
protsessidevaheliseks suhtluseks
Mälu loogiline jaotus
• Loogiline aadress - programmide poolt kasutatav
aadressiruum, nimetatakse ka virtuaalseks
aadressiruumiks
• Programmid koosnevad tihti moodulitest.
Selliseid mooduleid võivad erinevad programmid
omavahel jagada. Osad neist on loetavad ja osad
sisaldavad muutmist vajavaid andmeid
• Mäluhaldus vastutab sellise loogilise jaotuse
organiseerimise eest, mis erineb füüsilisest
aadressruumist
• Üks moodus seda teostada on segmentimine
Mälu füüsiline jaotamine
• Mälu on tavaliselt jaotatud peamäluks ja
sekundaarseks mäluks
• Mäluhaldus tegeleb mälu liigutamisega nende
mälude vahel
• Sekundaarne mälu – andmete pikemaajaliseks
hoidmiseks mõeldud mälu (kettad,
magnetlindid)
• Välismälu – CD, DVD, välised kettad
• Virtuaalmälu (oli eespool)
Mälu tihendamine, pakkimine
• Tehnikat, mis võimaldab hõivatud piirkondi
ümber tõsta suurema vaba ruumi tekkimiseks
kutsutakse tihendamiseks
• Mälu saab tihendada järgmistel tingimustel:
– Niipea, kui töö (tegum) lõpeb;
– Kui uut tööd ei saa mällu laadida mälu killustatuse
tõttu;
– Teatud ajaperioodi möödumisel.
Töötava protsessi juhtbloki andmestruktuuri vaatamine Kohaliku tuuma „debugging“ käivitamiseks WinDbg-ga tuleb valida File menüüst Kernel Debug, valida Local vaheleht ja klikkida OK. Avaneva akna allosas peaks olema viip lkd> ja aknake, kuhu saab käske tippida. Käskusid saab vaadata Debugger.chm failist (abiinfo fail), lisaks saab kasutada dt (display type) käsku ca 1000 parameetriga. Kernel sümbol fail on vaja enne seadistada.
Kohaliku tuuma „debugging“ käivitamiseks WinDbg-ga tuleb valida File menüüst Kernel Debug, valida Local vaheleht ja klikkida OK. Avaneva akna allosas peaks olema viip lkd> ja aknake, kuhu saab käske tippida. Käskusid saab vaadata Debugger.chm failist (abiinfo fail), lisaks saab kasutada dt (display type) käsku ca 1000 parameetriga. Kernel sümbol fail on vaja enne seadistada.
Kerneli struktuuride tüübi info saab käsuga dt nt!_*
Katkestuste objekti struktuuri saab käsuga dt nt!_*interrupt*:, selle väljundi esimene rida on „nt!_KINTERRUPT, selle sisu saab omakorda vaadata dt nt!_KINTERUPT: käsuga jne. Alamstruktuuride vaatamiseks peaks lisama võtme –r.
Aktiivsete protsesside (eprocess) struktuuride vaatamine: dt nt!_eprocess. Väljundi esimene rida on pcb, selle struktuuri saab vaadata dt _kprocess käsuga
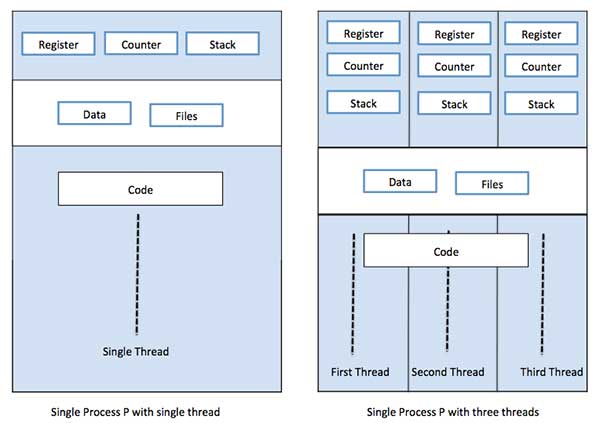
A thread is a flow of execution through the process code, with its
own program counter, system registers and stack. A thread is also called
a light weight process. Threads provide a way to improve application
performance through parallelism. Threads represent a software approach
to improving performance of operating system by reducing the overhead
thread is equivalent to a classical process.
Each thread belongs to exactly one process and no thread can exist
outside a process. Each thread represents a separate flow of
control.Threads have been successfully used in implementing network
servers and web server. They also provide a suitable foundation for
parallel execution of applications on shared memory multiprocessors.
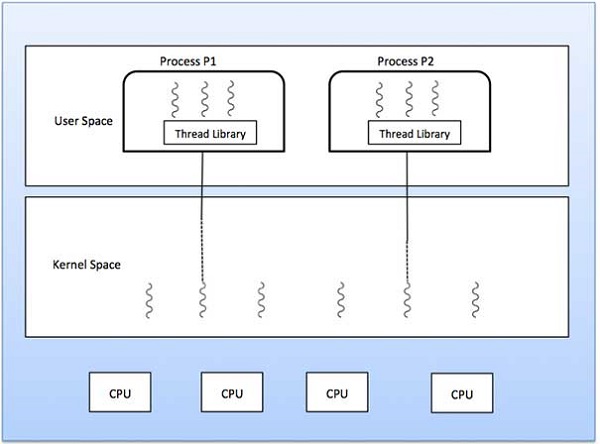
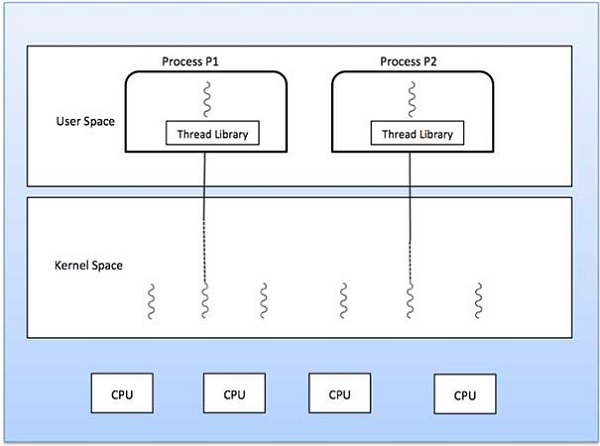
Folowing figure shows the working of the single and multithreaded
processes.
Difference between Process and Thread
S.N.
Process
Thread
1
Process is heavy weight or resource intensive.
Thread is light weight taking lesser resources than a process.
1
Process switching needs interaction with operating system.
Thread switching does not need to interact with operating system.
1
In multiple processing environments each process executes the same code but has its own memory and file resources.
All threads can share same set of open files, child processes.
1
If one process is blocked then no other process can execute until the first process is unblocked.
While one thread is blocked and waiting, second thread in the same task can run.
1
Multiple processes without using threads use more resources.
Multiple threaded processes use fewer resources.
1
In multiple processes each process operates independently of the others.
One thread can read, write or change another thread's data.
Advantages of Thread
Thread minimize context switching time.
Use of threads provides concurrency within a process.
Efficient communication.
Economy- It is more economical to create and context switch threads.
Utilization of multiprocessor architectures to a greater scale and efficiency.
Types of Thread
Threads are implemented in following two ways
User Level Threads -- User managed threads
Kernel Level Threads -- Operating System managed threads acting on kernel, an operating system core.
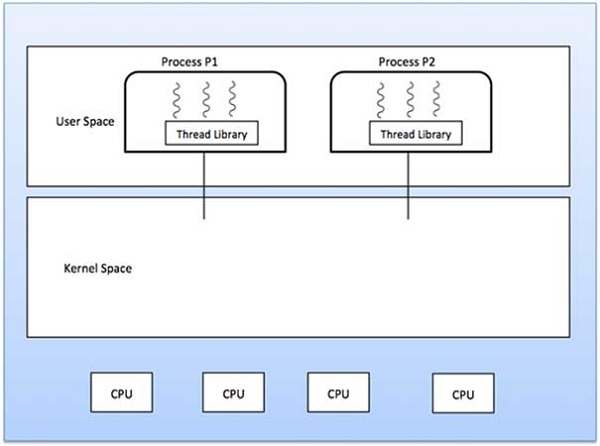
User Level Threads
In this case, application manages thread management kernel is not
aware of the existence of threads. The thread library contains code for
creating and destroying threads, for passing message and data between
threads, for scheduling thread execution and for saving and restoring
thread contexts. The application begins with a single thread and begins
running in that thread.
Advantages
Thread switching does not require Kernel mode privileges.
User level thread can run on any operating system.
Scheduling can be application specific in the user level thread.
User level threads are fast to create and manage.
Disadvantages
In a typical operating system, most system calls are blocking.
Multithreaded application cannot take advantage of multiprocessing.
Kernel Level Threads
In this case, thread management done by the Kernel. There is no
thread management code in the application area. Kernel threads are
supported directly by the operating system. Any application can be
programmed to be multithreaded. All of the threads within an application
are supported within a single process.
The Kernel maintains context information for the process as a whole
and for individuals threads within the process. Scheduling by the Kernel
is done on a thread basis. The Kernel performs thread creation,
scheduling and management in Kernel space. Kernel threads are generally
slower to create and manage than the user threads.
Advantages
Kernel can simultaneously schedule multiple threads from the same process on multiple processes.
If one thread in a process is blocked, the Kernel can schedule another thread of the same process.
Kernel routines themselves can multithreaded.
Disadvantages
Kernel threads are generally slower to create and manage than the user threads.
Transfer of control from one thread to another within same process requires a mode switch to the Kernel.
Multithreading Models
Some operating system provide a combined user level thread and Kernel
level thread facility. Solaris is a good example of this combined
approach. In a combined system, multiple threads within the same
application can run in parallel on multiple processors and a blocking
system call need not block the entire process. Multithreading models are
three types
Many to many relationship.
Many to one relationship.
One to one relationship.
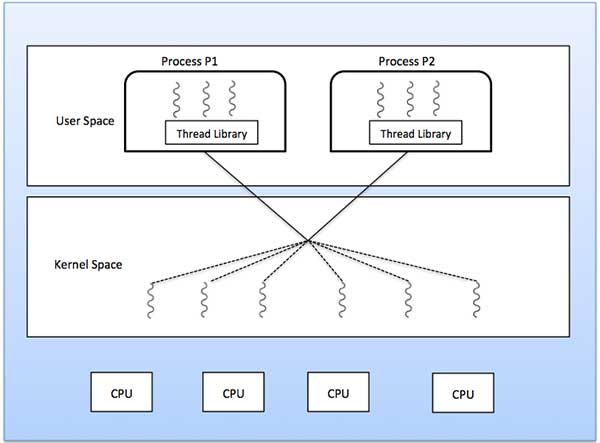
Many to Many Model
In this model, many user level threads multiplexes to the Kernel
thread of smaller or equal numbers. The number of Kernel threads may be
specific to either a particular application or a particular machine.
Following diagram shows the many to many model. In this model,
developers can create as many user threads as necessary and the
corresponding Kernel threads can run in parallels on a multiprocessor.
Many to One Model
Many to one model maps many user level threads to one Kernel level
thread. Thread management is done in user space. When thread makes a
blocking system call, the entire process will be blocks. Only one thread
can access the Kernel at a time,so multiple threads are unable to run
in parallel on multiprocessors.
If the user level thread libraries are implemented in the operating
system in such a way that system does not support them then Kernel
threads use the many to one relationship modes.
One to One Model
There is one to one relationship of user level thread to the kernel
level thread.This model provides more concurrency than the many to one
model. It also another thread to run when a thread makes a blocking
system call. It support multiple thread to execute in parallel on
microprocessors.
Disadvantage of this model is that creating user thread requires the
corresponding Kernel thread. OS/2, windows NT and windows 2000 use one
to one relationship model.
Difference between User Level & Kernel Level Thread
S.N.
User Level Threads
Kernel Level Thread
1
User level threads are faster to create and manage.
Kernel level threads are slower to create and manage.
2
Implementation is by a thread library at the user level.
Operating system supports creation of Kernel threads.
3
User level thread is generic and can run on any operating system.
Kernel level thread is specific to the operating system.
4
Multi-threaded application cannot take advantage of multiprocessing.
Definitsioon - Protsessi planeermine on protsessi haldaja tegevus, mis haldab jooksvate protsesside eemaldamist CPUst ja mõne teise protsessi valimine kindla strateegia põhjal. Plaanimise järjekorrad - Viitab järjekorrale protsessis või seadmes. Kui protsess siseneb süsteemi, siis protsess pannakse töö järjekorda. See järjekord koosneb kõikidest protsessidest süsteemis. OS omab ka teisi järjekordi nagu seadmejärjekord. Seadmejärjekord on järjekord, mitu protsessi ootavad kindlat I/O seadet. Igal seadmel on oma seamdejärjekord.
This figure shows the queuing diagram of process scheduling.
Queue is represented by rectangular box.
The circles represent the resources that serve the queues.
The arrows indicate the process flow in the system.
Queues are of two types
Ready queue
Device queue
newly arrived process is put in the ready queue. Processes waits in
ready queue for allocating the CPU. Once the CPU is assigned to a
process, then that process will execute. While executing the process,
any one of the following events can occur.
The process could issue an I/O request and then it would be placed in an I/O queue.
The process could create new sub process and will wait for its termination.
The process could be removed forcibly from the CPU, as a result of interrupt and put back in the ready queue.
Two State Process Model
-Running When new process is created by Operating System that process enters into the system as in the running state. -Not Running Processes that are not running are kept in queue,
waiting for their turn to execute. Each entry in the queue is a pointer
to a particular process. Queue is implemented by using linked list. Use
of dispatcher is as follows. When a process is interrupted, that process
is transferred in the waiting queue. If the process has completed or
aborted, the process is discarded. In either case, the dispatcher then
selects a process from the queue to execute
Schedulers
Schedulers are special system softwares which handles process
scheduling in various ways.Their main task is to select the jobs to be
submitted into the system and to decide which process to run. Schedulers
are of three types
Long Term Scheduler
Short Term Scheduler
Medium Term Scheduler
Long Term Scheduler
It is also called job scheduler. Long term scheduler determines which
programs are admitted to the system for processing. Job scheduler
selects processes from the queue and loads them into memory for
execution. Process loads into the memory for CPU scheduling. The primary
objective of the job scheduler is to provide a balanced mix of jobs,
such as I/O bound and processor bound. It also controls the degree of
multiprogramming. If the degree of multiprogramming is stable, then the
average rate of process creation must be equal to the average departure
rate of processes leaving the system.
On some systems, the long term scheduler may not be available or
minimal. Time-sharing operating systems have no long term scheduler.
When process changes the state from new to ready, then there is use of
long term scheduler.
Short Term Scheduler
It is also called CPU scheduler. Main objective is increasing system
performance in accordance with the chosen set of criteria. It is the
change of ready state to running state of the process. CPU scheduler
selects process among the processes that are ready to execute and
allocates CPU to one of them.
Short term scheduler also known as dispatcher, execute most
frequently and makes the fine grained decision of which process to
execute next. Short term scheduler is faster than long term scheduler.
Medium Term Scheduler
Medium term scheduling is part of the swapping. It removes the
processes from the memory. It reduces the degree of multiprogramming.
The medium term scheduler is in-charge of handling the swapped
out-processes.
Schedulerite võrdlus
Konteksti vahetus
A context switch is the mechanism to store and restore the state or
context of a CPU in Process Control block so that a process execution
can be resumed from the same point at a later time. Using this technique
a context switcher enables multiple processes to share a single CPU.
Context switching is an essential part of a multitasking operating
system features.
When the scheduler switches the CPU from executing one process to
execute another, the context switcher saves the content of all processor
registers for the process being removed from the CPU, in its process
descriptor. The context of a process is represented in the process
control block of a process.
Context switch time is pure overhead. Context switching can
significantly affect performance as modern computers have a lot of
general and status registers to be saved. Content switching times are
highly dependent on hardware support. Context switch requires ( n + m )
bxK time units to save the state of the processor with n general
registers, assuming b are the store operations are required to save n
and m registers of two process control blocks and each store instruction
requires K time units.
Some hardware systems employ two or more sets of processor registers
to reduce the amount of context switching time. When the process is
switched, the following information is stored.
OS'i
ülesanne on protsesside haldus ehk OS peab jagama protsessidele ressursse,
võimaldama protsessidel vahetada informatsiooni teiste protsessidega ja
võimaldama sünkroniseerimist protsesside seas. Protsess on kasutajarakenduse töötav koopia ja protsesside
haldamiseks ning neile ressursside jagamiseks peab OS haldama iga protsessi
jaoks andmestruktuuri, mis kirjeldab protsessi identiteeti, staatust, seotud
ressursse, jne, et rakendada kontrolli protsessi üle. Protsessi iseloomustavad
järgmised omadused:
Identifikaator:
unikaalne number, mis eristab protsessi teistest protsessidest
Staatus:
näitab protsessi jooksvat seisundit (näiteks käivitatud)
Prioriteet:
prioriteet võrreldes teiste protsessidega
Programmiloendur:
järgmise käsu aadress, mis tuleb käivitada
Mälulokaator:
mäluaadressid programmi koodi ja andmete asukohta
Kontekstandmed:
protsessori registrite seis protsessi käivitamisel
S/V
staatuse info: info täitmisel S/V päringutest, protsessiga seotud S/V seadmed,
protsessi poolt avatud failide loetelu, jne.
Aruandlusinfo:
kasutatud protsessori aeg, ajapiirangud, jne.
Seda infot
talletatakse andmestruktuuris, mida nimetatakse protsessi juhtplokiks (Process Control Block), mida haldab OS.
Protsessi juhtplokk sisaldab piisavalt infot, et protsessi saab vajadusel
katkestada ja hiljem jätkata, nagu oleks vahepeal juhtunud katkestus. Kui
protsess katkestatakse siis jooksvad väärtused nagu programmiloendur ja
protsessori registrite seis salvestatakse vastavates protsessi juhtploki
väljades ja protsessi seisund muudetakse täitmisel (Execution) staatusest kas
blokeerituks (Blocked) või täitmiseks valmis (Ready) staatusesse.
Joonis -
Protsesside staatuse ümberlülitumise võimalused (Allikas: Learning Materials for Information Technology Professionals
(EUCIP-Mat))
Täitmiseks valmis staatus tähendab, et protsess on
ajastatud tööjärjekorda ja ootab protsessoriressursi vabanemist, et oma tööga
edasi minna
Täitmisel protsess kasutab parajasti talle
määratud protsessoriressurssi.
Blokeeritud seisu seatakse süsteemikutse
käivitanud protsess, mis ootab mingi S/V operatsiooni täitmist oma töö
jätkamiseks.
Selgitav video protsessi töötamise kohta inglise keeles. 1.osa
Kui kernel suutis mingi asja tööle panna, siis tema jaoks on midagi eraldatud


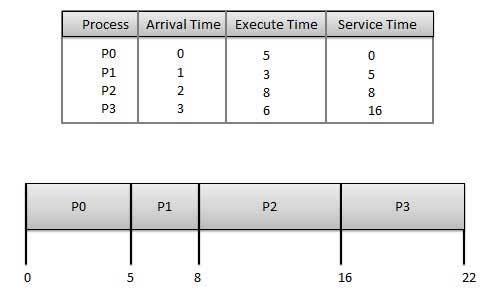 Wait time of each process is following
Wait time of each process is following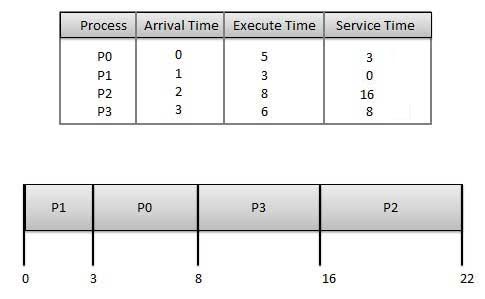 Wait time of each process is following
Wait time of each process is following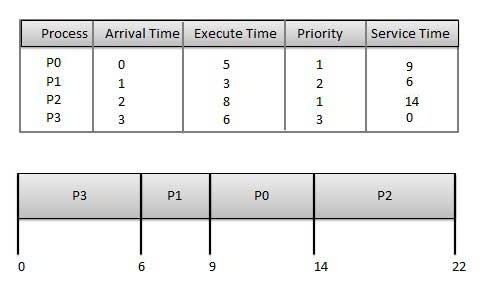 Wait time of each process is following
Wait time of each process is following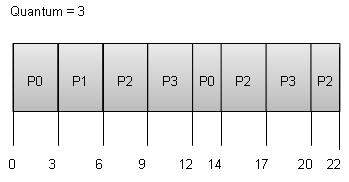 Wait time of each process is following
Wait time of each process is following





